Equalization & fairness
What it is
Equalization is the set of soft rules that steer rostering toward fairness — spreading off-days, overtime, and shift types more evenly across a team — without ever blocking anyone. They only adjust a candidate's ranking score.
Why it exists
If allocation only optimised skill and availability, the same reliable people would absorb the most overtime and the worst shifts. Equalization nudges the engine to share the load: someone already carrying more overtime than their teammates scores lower for more of it, so the planner naturally rotates fairly — while hard limits still protect everyone.
Key concepts & terms
- Cohort — the group a candidate is compared against: their home terminal, over the last 30 days. (Not the business unit, department, or skill.)
- Off-day equalization — scores how a candidate's off-days compare to their cohort.
- Overtime equalization — scores how a candidate's accrued overtime compares to their cohort.
- Shift-time equalization — scores how a candidate's spread of shift times (morning/day/evening/night) compares to their cohort.
- Working-hours priority — scores a candidate against a fixed weekly target, not the team.
- Overtime-window — an absolute steer that pushes work away from people already near their overtime threshold.
- Neutral score — the fallback score used when there isn't enough cohort data to judge fairly.
- Snapshot — the per-run pre-built data; cohort baselines only exist inside a prepared run (see Rosters & allocation runs).
How it works
Instead of a yes/no gate, each equalization rule scores a candidate by comparing them to their cohort (home terminal, last 30 days): off-days taken, overtime accrued, and the spread of shift times. A candidate far from the cohort average scores differently, so the planner rotates fairly. Working-hours priority is the exception — it compares to a fixed weekly target rather than the team, so it needs no cohort. Overtime-window is an absolute steer that eases work away from people near their overtime threshold before the hard cap bites.
Live on the snapshot path, neutral on the fallback path
This is the precise truth, and it matters:
- The three cohort rules — off-day, overtime, and shift-time equalization — are fully live when a run's snapshot is populated (the normal production path). When evaluated outside a populated run (the database-fallback path, used for ad-hoc or preview checks), they have no cohort to compare against and deliberately return a neutral score. So they are live on the snapshot path, neutral on the fallback path — not "live everywhere," and not "stubbed."
- Working-hours priority and overtime-window are fully live on both paths, because they aren't cohort-relative.
A historical note you may see elsewhere: these rules were once shipped as always-pass stubs. That is out of date — the stub behaviour no longer exists in the code; the rules compute real cohort-relative scores.
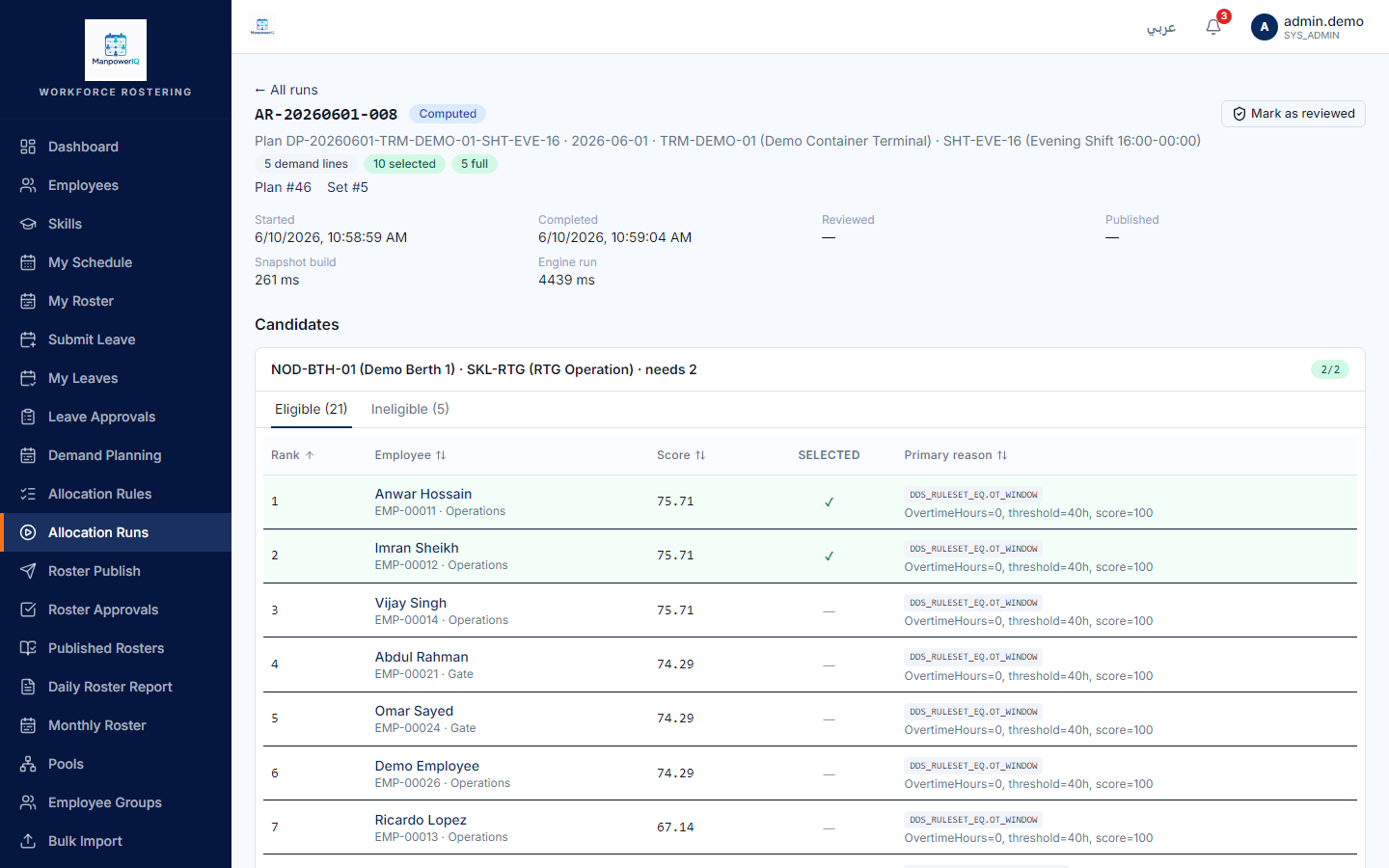
Rules & what's enforced
- Equalization never blocks. Every one of these is a soft rule — it adjusts the ranking score and nothing else. Only hard rules make a candidate ineligible.
- Small cohorts fall back to neutral. If a cohort is below the minimum size (default 5), the rule scores neutral rather than judging on too little data.
- No fixed "more is better" direction. A business unit can tune whether higher utilisation is rewarded or rested — the scores aren't forced into a single ordering.
- Cohort is per home terminal, over a 30-day window — not per department, skill, or business unit.
What's live vs planned
- Live (in production runs): all five rules. The three cohort rules score live on the run snapshot; working-hours-priority and overtime-window score live on every path.
- Degrades by design: outside a populated run the three cohort rules return a neutral score (no cohort available).
- A skill-based cohort is a reserved idea for a future version; today the cohort is the home terminal.
- UI shows a score, not the tier. The engine sorts each candidate into a Below / At / Above cohort tier, but the app surfaces only the numeric soft-score on the candidate card — the tier label and cohort comparison live in the run / execution log, not the UI (finding F8).
Related
- Allocation rules — the soft-scoring framework these rules feed into.
- Rosters & allocation runs — the run snapshot the cohort rules depend on.