Rosters & allocation runs
What it is
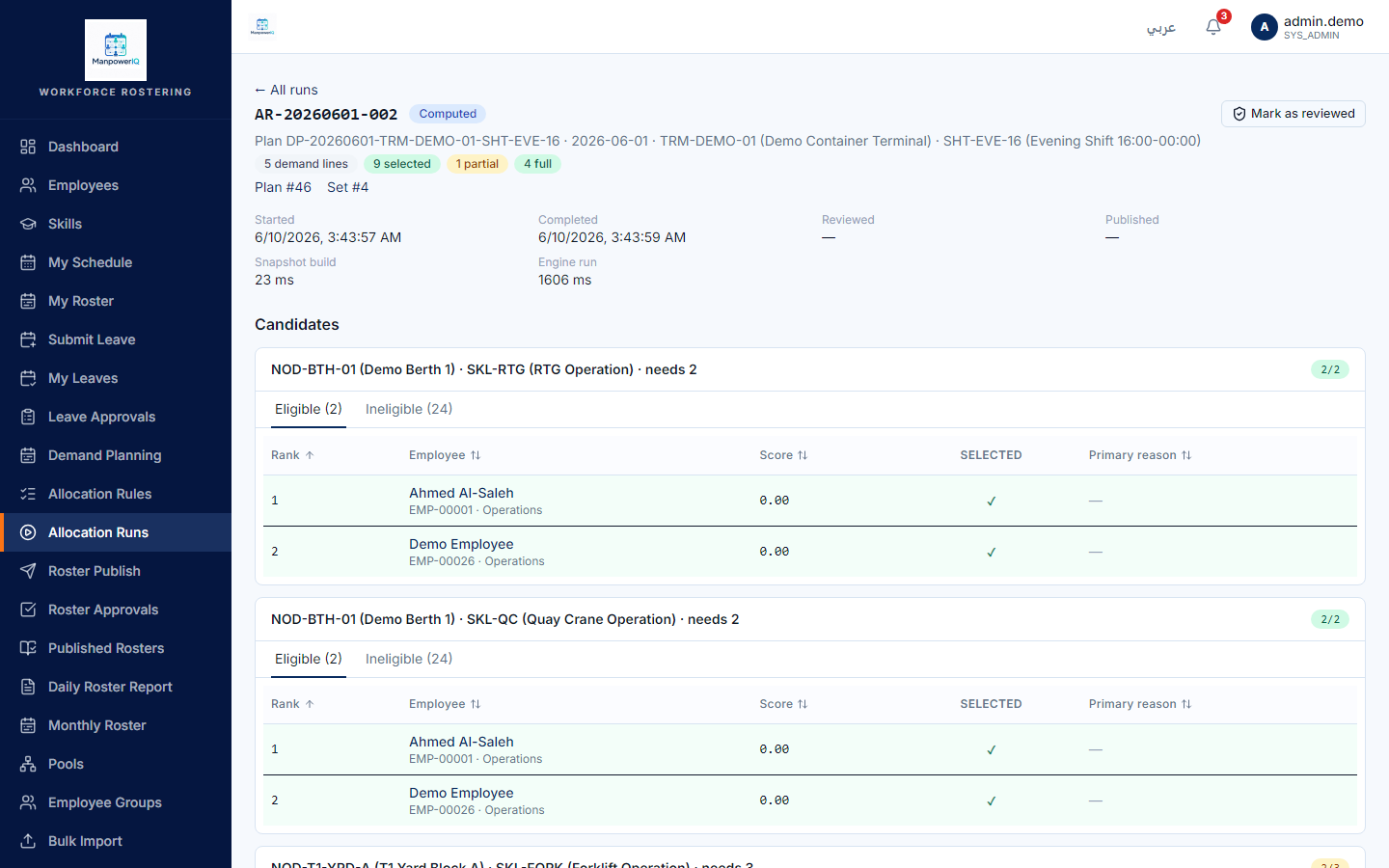
An allocation run executes the allocation rules against a confirmed demand plan and produces, for every open slot, a ranked list of candidates with the best ones selected. A run is not the published roster — it is the computation that proposes who should be selected, which a planner then reviews, locks, and (separately) publishes.
Why it exists
Filling a demand plan by hand is slow and hard to justify. A run does it in one pass — evaluating every candidate against every slot through the rules — and records why each person was eligible or not, so the result is explainable and repeatable. Separating "compute" from "review" and "publish" keeps a human in charge of what actually goes live.
Key concepts & terms
- Allocation run — one execution of the rules against a (demand plan × rule set).
- Candidate row — one evaluated employee × demand line, carrying its eligibility, score, and rank.
- Eligible vs selected — eligible means the candidate passed all hard rules; selected means they were among the top-ranked eligibles chosen to fill that line's head count. Eligible is "could be used"; selected is "was chosen."
- Snapshot — the per-run, pre-built data the rules read, so the run avoids tens of thousands of database round-trips.
- Rerun — running again; it creates a brand-new run and never changes the old one.
- Run state —
Draft,Computed,Reviewed,Locked, orFailed.
How it works
A run separates machine work from human judgement:
stateDiagram-v2
[*] --> Draft: create
Draft --> Computed: execute (the engine runs the rules)
Draft --> Failed: engine error
Computed --> Reviewed: a planner reviews the ranked candidates
Computed --> Failed: mark failed
Reviewed --> Locked: a planner locks the run
note right of Locked
Rerun spawns a NEW Draft run.
This run is never modified in place.
end noteThe engine evaluates every active employee against every demand line, ranks the eligible ones per line, and marks the top head count as selected. It writes one candidate row per evaluation, with the eligibility, score, rank, and the evidence behind the decision.
Why the snapshot? A big run can be on the order of hundreds of employees × ~100 lines × ~11 rules — roughly half a million evaluations. If every evaluation queried the database for skills, certs, prior shifts, leave, and so on, that would be tens of thousands of round-trips. So the run pre-builds one in-memory snapshot (a handful of queries) that all the rules read from. It trades a little memory for collapsing ~50,000 queries into a few.
Where a run sits in the bigger pipeline:
flowchart LR
D["Demand plan (Confirmed)"] --> R["Allocation rules"]
R --> Run["Allocation run — ranks & selects candidates"]
Run --> P["Publish → roster (a separate step)"]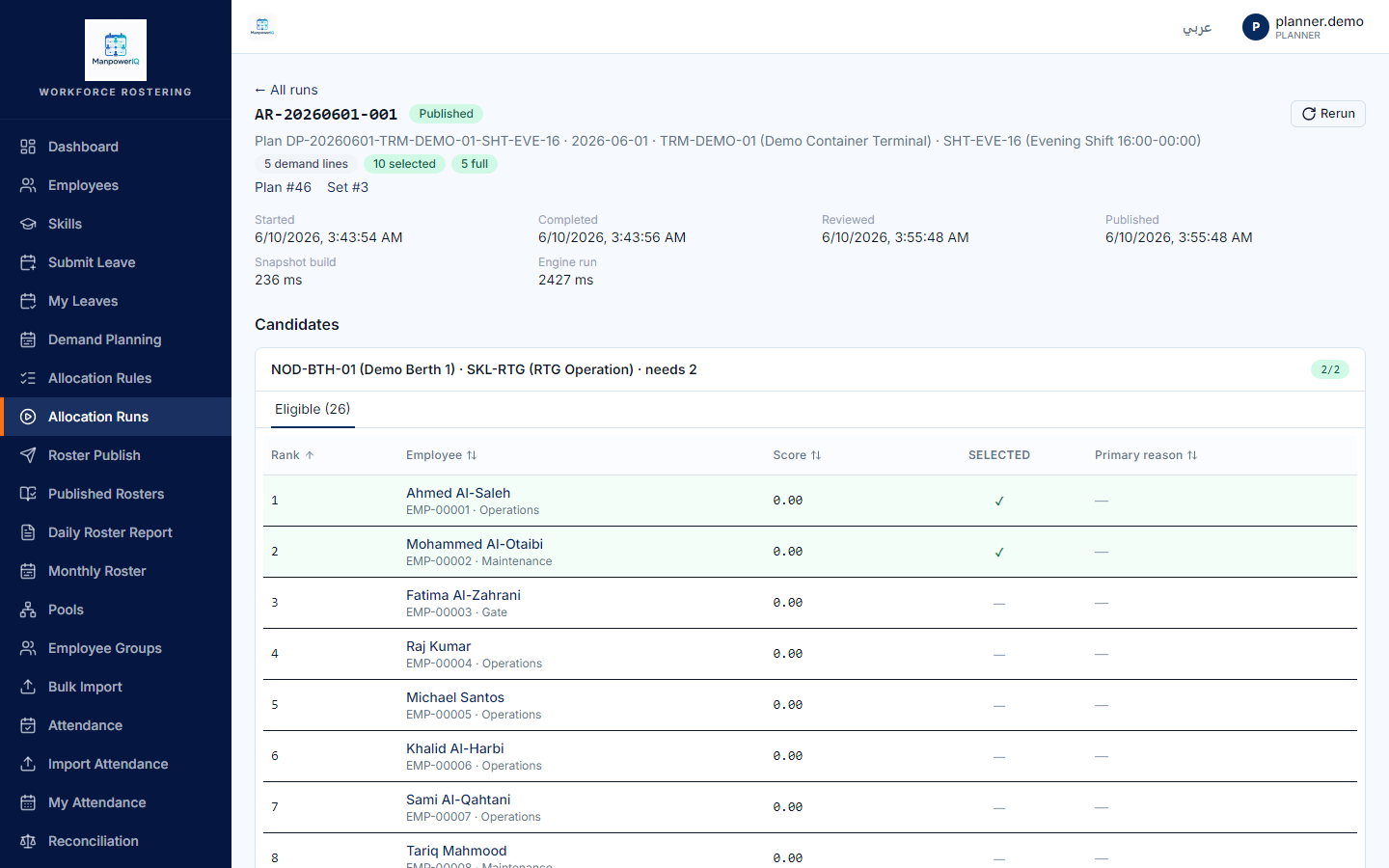
Rules & what's enforced
- A run does not publish and does not write shift assignments. It produces ranked/selected candidate rows only. Turning a run into a live roster is a separate publish step (covered by the approvals & publish area).
- State order is enforced: execute needs
Draft, review needsComputed, lock needsReviewed. Out-of-order calls are refused (HTTP 409), not silently accepted. - Rerun never mutates. It spawns a fresh
Draftrun on the same plan and rule set; the original keeps its state (it can stay Locked) so you can compare. - Selection is deterministic — eligibles are ranked by score (then employee id) so re-runs are stable.
- Ineligible candidates are only shown to users with the debug permission.
Who can see why someone was excluded: the per-rule hard-fail reason is gated to admin/debug access (
allocation_run.debug, SYS_ADMIN). A planner sees only the eligible candidates and who was selected — not the exclusion reasons. This bites most on an unfilled run, where the diagnosis a planner needs (e.g. "no lending rule", "cert expired") is exactly the part they can't see (finding F6).Three different "Locked"/"Published" states — never conflate them: a demand plan can be Locked, an allocation run can be Locked, and a published roster is Published. They live on three different things and mean three different things. Locking a run is not locking the demand plan, and neither one publishes a roster. Note: demand-plan Locked is a defined state with no current runtime path, whereas run Locked and roster Published are both reachable and were runtime-verified (Phase 3).
What's live vs planned
- Live: the run engine (Draft→Computed/Failed), the snapshot, the human-gated transitions (Computed→Reviewed→Locked), rerun, the eligible/ineligible candidate read API, retention clean-up, and the runs list / run-detail / state-pill / lock & rerun dialogs.
- Partial: the web trigger-run (Execute) button arrived late in the sprint (the execute endpoint itself is live backend); and one snapshot section (shift-mix cohort) ships empty, deferred to the equalization work — rules that need it fall back to a neutral score.
Related
- Demand — the confirmed plan a run fills.
- Allocation rules — the hard/soft rules a run executes.
- Equalization & fairness — the fairness rules that depend on the run snapshot.
- Pools & cross-pooling — a hard gate evaluated during the run.